微博,微信,QQ当中,好友之间的关系就需要用图这种数据结构来存储。有关图的算法也比较多:图的搜索,最短路径,最小生成树,二分图等等。这篇文章开始总结图的知识点。
什么是图
图中的元素叫做顶点,元素与元素之间的连线,叫做边。
用图的结构来表示微信用户之间的关系,微信用户就是图中的顶点,互为好友的用户,就用边来表示。微信用户有多少个好友,对应图中顶点的度。跟顶点相连接的边的个数,叫做顶点的度。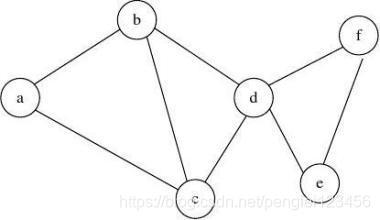
用图的结构来表示微博用户之间的关系,同样用边来关联用户。但是,微博用户的关系有关注和被关注之分,所以我们需要在边上加上箭头,用来表示这种关系。关注了谁,箭头指向谁,谁关注了你,谁的箭头就指向你。由于边有了方向的概念,所以这种图的结构叫做有向图,没有方向概念的叫做无向图。
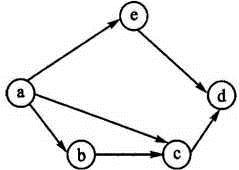
有向图中也有度的概念,称之为出度和入度。指向顶点的个数叫做入度,从顶点指向别处的个数叫做出度。
用图的结构来表示QQ用户之间的关系。QQ好友之间除了建立好友关系以外,还有一个亲密功能,用来表示用户之间的亲密度。当我们在图的边上加上权重的标识,就可以用来表示QQ好友亲密度,这种加上权重的图叫做带权图。

图存储
邻接矩阵
邻接矩阵底层依赖一个二维数组。对于无向图,如果顶点 M 到顶点 N 之间有边,那么我们将数组中 A[M][N] 和 A[N][M] 的值记为 1 。 对于有向图,如果顶点 M 指向顶点 N 之间,那么我们将数组中 A[M][N] 的值记为 1 。 对于带权无向图,如果顶点 M 到顶点 N 的权重为 5,那么我们将数组中 A[M][N] 和 A[N][M] 的值记为 5 。
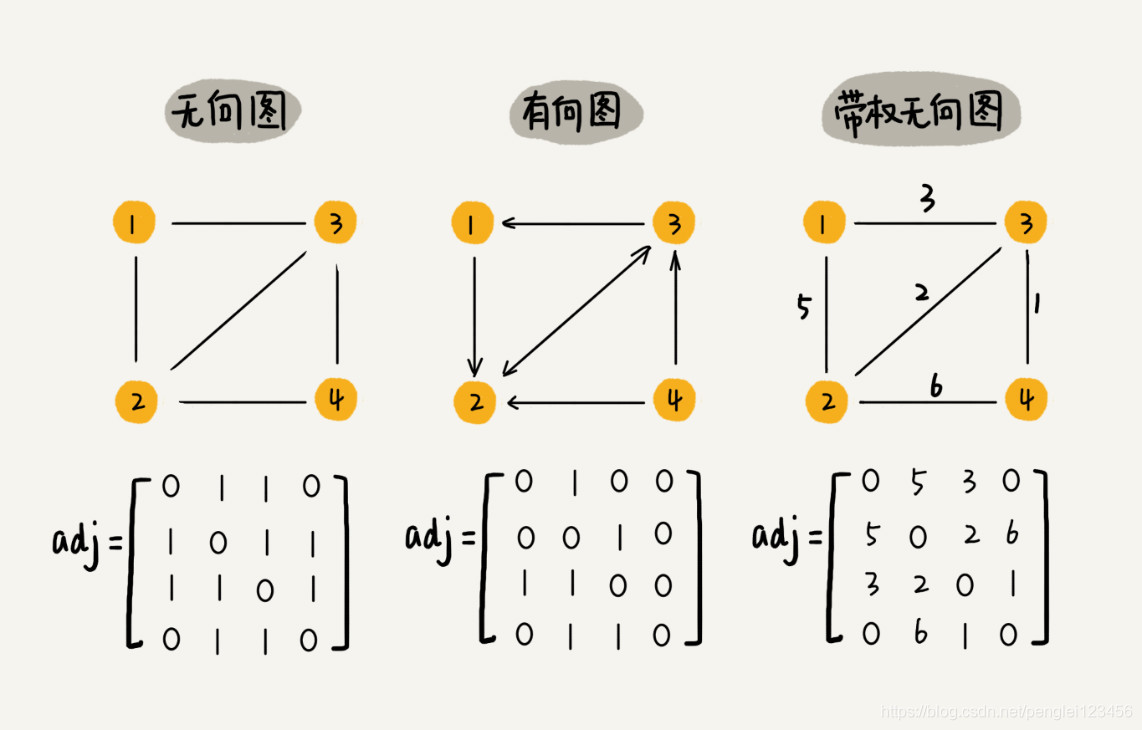
邻接矩阵的标识方法简单直观,但是浪费大量的无用空间。对于无向图来说,A[M][N] 和 A[N][M] 只要其中一个的值为 1 就能表示这种关系。也就是说,每种关系都表示了两边,其实只需要一半的空间就够了。
如果存储的是稀疏图,顶点多,边少,那么空间的浪费就更严重了。
邻接表
邻接表存储结构如下图所示,类似一个散列表。对于有向图来说:邻接表中的每一个顶点都维护了一个链表,链表中存储的是该顶点指向的顶点集合。对于无向图来说,链表中存储的就是与该顶点有连线的顶点集合。
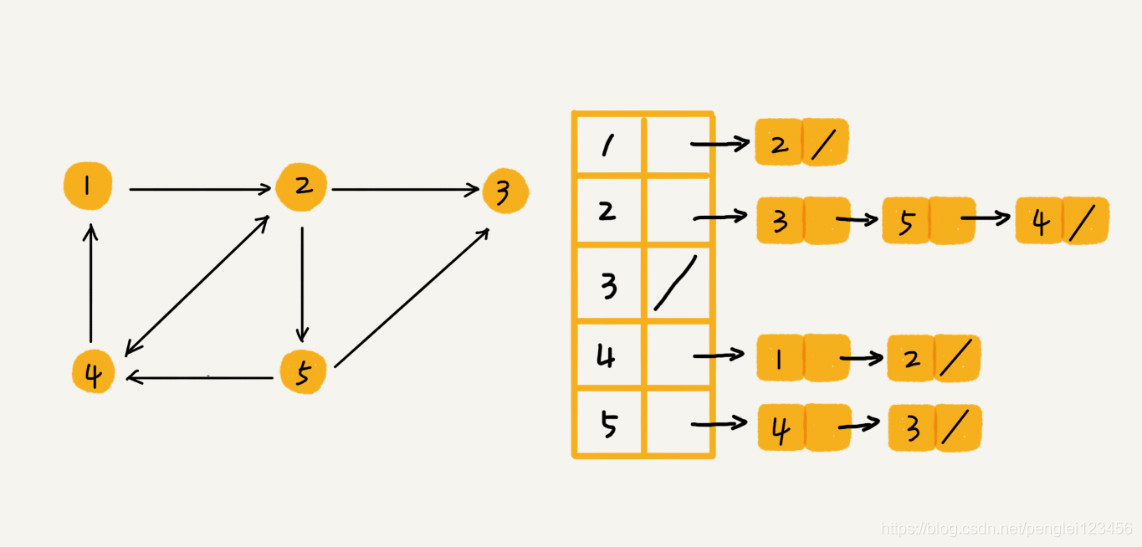
邻接表存储节省空间但是查询的时候比较浪费时间。但是,我们可以对邻接表做进行优化。对于邻接表中顶点维护的链表,我们可以用跳表或者是平衡二叉查找树的结构来实现。我们也可以将链表改成有序动态数据,通过二分法查找顶点。
综合延伸
如何存储微博之间的好友关系。
数据结构是为算法服务的,所以我们要先明确微博好友之间存在哪些操作。
1:判断用户 A 是否关注用户 B
2:判断 A 是否为用户 B 的粉丝。
3:用户 A 关注用户 B
4:用户 A 取消关注用户 B
5:按照首字母排序查询用户 A 关注的用户。
6:按照首字母排序查询用户 A 的粉丝。
首先,微博社交关系是一张稀疏图,所以用邻接表。
其次,我们用邻接表表示微博中关注用户的关系,链表中存储用户关注的人。同时用一张逆邻接表表示微博中用户粉丝的关系,链表中存储用户的粉丝。
如图所示: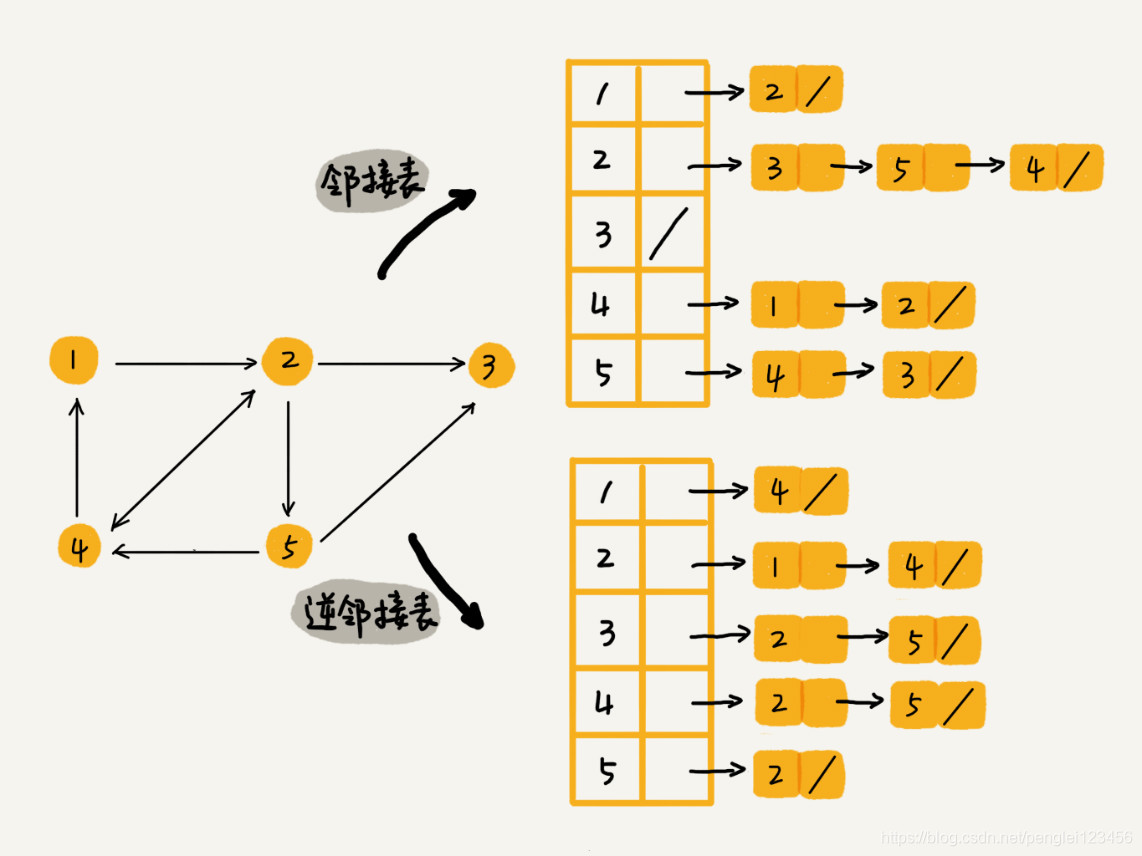
由于需要按照首字母排序查询粉丝或者关注用户列表,所以选择用跳表这种结构存储存储数据。
如果数据量大,我们需要采用哈希算法,进行数据分片存储。例如1,2,3这些顶点的数据存储在机器 1上。4,5这些顶点的数据存储在机器 2 上。图示如下: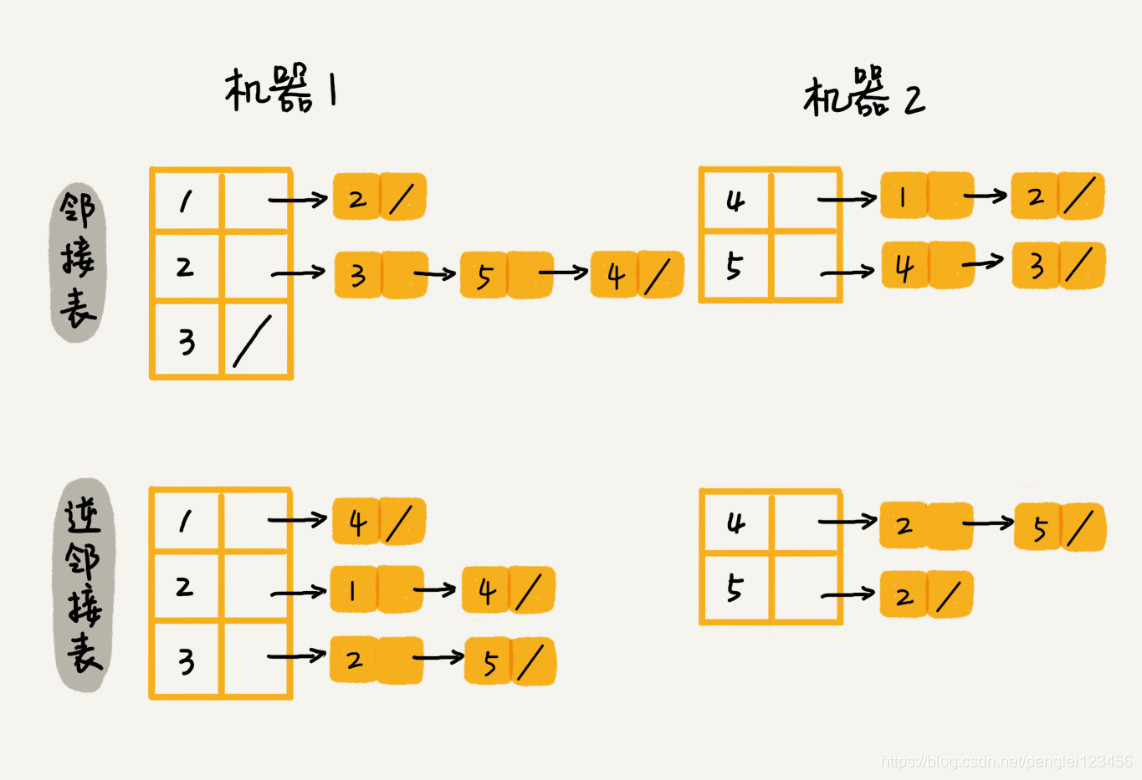
也可以将数据存储在数据库中,此时创建一张表,两个字段分别表示关注人和被关注人。
回顾一下:今天总结了图,无向图,有向图,带权图,顶点,边,度,入度,出度,权重等等。总结了两种存储方式:邻接矩阵和邻接表。
总结
本文创作灵感来源于 极客时间 王争老师的《数据结构与算法之美》课程,通过课后反思以及借鉴各位学友的发言总结,现整理出自己的知识架构,以便日后温故知新,查漏补缺。
初入算法学习,必是步履蹒跚,一路磕磕绊绊跌跌撞撞。看不懂别慌,也别忙着总结,先读五遍文章先,无他,唯手熟尔~
与诸君共勉